01. NL 조인
- 조인의 기본은 NL 조인이다.
- 중첩 루프문의 수행 구조를 사용한다.
- 양쪽 테이블의 인덱스를 이용하는 조인이다. '인덱스를 이용한 조인 방식'
NL 조인 메커니즘
- 인덱스 사용 : NL 조인은 양쪽 테이블 모두 인덱스를 사용한다.
- Outer 테이블(Driving)을 순차적으로 읽어 조건을 만족하는 행을 Inner 테이블에 탐색한다.
SELECT e.사원명, c.고객명, c.전화번호
FROM 사원 e, 고객 c
WHERE e.입사일자 >= '19960101'
AND c.관리사원번호 = e.사원번호
(1) 사원 인덱스에서 조건에 맞는 첫 번째 레코드를 찾는다.
(2) 인덱스에서 읽은 ROWID로 사원 테이블 레코드를 찾는다.
(3) 사원 테이블에서 읽은 사원번호로 고객 인덱스를 탐색한다.
(4) 고객 인덱스에서 읽은 ROWID로 고객 테이블 레코드를 찾는다.
(5) 사원 인덱스에서 입사일자 >= '19960101' 인 모든 레코드에 대해 (1)~(4) 반복한다.

NL 조인의 특징
- 랜덤 액세스 위주, 레코드 하나를 읽으려고 블록을 통째로 읽는 랜덤 액세스 방식이기 때문에, 인덱스 구성이 완벽하더라도 대량 데이터 조인할 때는 불리하다.
- 한 레코드씩 순차적으로 진행, 부분범위 처리가 가능하여, 큰 테이블을 조인하더라도 매우 빠른 응답 속도를 낼 수 있다.
- 인덱스 구성 전략이 중요, 조인 컬럼에 대한 인덱스가 있느냐 없느냐 등 어떻게 구성 됐느냐에 따라 조인 효율이 크게 달라진다.
NL 조인 주용도
- 소량 데이터를 주로 처리하거나 부분범위 처리가 가능한 온라인 트랜잭션 처리 시스템에 적합한 조인 방식
02. 소트 머지 조인
- 조인 컬럼에 인덱스가 없거나, 대량 데이터 조인이어서 인덱스가 효과적이지 않을 때, 옵티마이저는 NL 조인 대신 소트 머지 조인이나 해시 조인을 선택한다.
- 해시 조인을 잘 사용하지만, 해시 조인을 사용할 수 없을 상황에서 소트 머지 조인을 사용한다.
- 소트 머지 조인과 해시 조인을 이해하기 위해서는 SGA과 PGA에 대해서 알아야 한다.
SGA (System Global Area)
- 공유 메모리 영역인 SGA에 캐시 된 데이터는 여러 프로세스가 공유할 수 있지만, 동시에 액세스 할 수 없다.
- 동시에 액세스하려는 프로세스 간 액세스를 직렬화하기 위한 Lock 메커니즘으로서 Latch가 존재한다.
PGA (Private Global Area)
- 각 오라클 서버 프로세스에 할당된 메모리 영역인 PGA는, 프로세스에 종속적인 고유 데이터를 저장하는 용도로 사용한다.
- PGA 공간이 작아 데이터를 모두 저장할 수 없을 때는 Temp 테이블스페이스를 이용한다.
- 따라서 다른 프로세스와 공유하지 않는 독립적인 메모리 공간이므로 래치 메커니즘이 불필요하다. 같은 양의 데이터를 읽더라도 SGA 버퍼캐시에서 읽는 때보다 훨씬 빠르다.
소트 머지 조인 메커니즘
- 소트 단계 : 양쪽 집합을 조인 컬럼 기준으로 정렬한다.
- 머지 단계 : 정렬한 양쪽 집합을 서로 머지한다.
SELECT /*+ ordered use_merge(c) */
e.사원번호, e.사원명, e.입사일자, c.고객명, c.전화번호
FROM 사원 e, 고객 c
WHERE c.관리사원번호 = e.사원번호
AND e.입사일자 >= '19960101'
AND e.부서코드 = 'Z123'
AND c.최종주문금액 >= 20000
(1) 사원 데이터를 읽어 조인컬럼인 사원번호순으로 정렬하여, PGA 영역에 할당된 Sort Area에 저장한다.
(2) 고객 데이터를 읽어 조인컬럼인 관리사원번호순으로 정렬하여, PGA 영역에 할당된 Sort Area에 저장한다.
(3) PGA에 저장한 사원 데이터를 스캔하면서 PGA에 저장된 고객 데이터와 조인한다.
(3-1) 고객 데이터가 정렬되어 있기 때문에, 사원 데이터를 기준으로 고객 데이터를 매번 Full Scan 하지 않는다.
소트 머지 조인이 빠른이유
- Sort Area에 미리 정렬해 둔 자료구조를 이용한다는 점만 다를 뿐 조인 프로세싱 자체는 NL 조인과 동일하다.
- (NL 조인 단점) 조인 과정에서 액세스 하는 모든 블록을 랜덤 액세스 방식으로 건건이 DB 버퍼 캐시를 경유해서 읽는다. 읽는 모든 블록에 래치 획득 및 캐시버퍼 체인 스캔 과정을 거친다. 버퍼캐시에서 찾지 못한 블록은 건건이 디스크에서 읽는다.
- (소트 머지 조인) 양쪽 테이블로부터 조인 대상 집합을 일괄적으로 읽어 PGA에 저장한 후 조인한다. 그 과정에서 래치 획득 과정이 없다.
- 소트 머지 조인도 양쪽 테이블로부터 조인 대상 집합을 읽을 때 DB 버퍼캐시를 경유하고 인덱스도 사용한다. 이 과정에서 버퍼캐시 탐색 비용과 랜덤 액세스 부하는 동일하다.
소트 머지 조인 주용도
- 조인 컬럼에 인덱스가 없거나, 대량 데이터 조인이어서 인덱스가 효과적이지 않을 때
- 해시 조인이 빠르기 때문에 해시 조인을 대부분 사용하지만, 조인 조건식이 등치(=) 조건이 아닐 때 해시조인을 사용할 수 없다.
- 조인 조건식이 등치(=) 조건이 아닌 대량 데이터 조인
- 조인 조건식이 아예 없는 조인 (Cross Join, 카테시안 곱)
03. 해시 조인
- 소트 머지 조인과 해시 조인은 대량 데이터를 조인할 때 NL 조인보다 빠르고, 일정한 성능을 보인다.
- 소트 머지 조인은 항상 양쪽 테이블을 정렬하는 부담이 있지만, 해시 조인은 그런 부담도 없다.
해시 조인 메커니즘
- Build 단계 : 작은 쪽 테이블을 읽어 해시 테이블을 생성한다.
- Probe 단계 : 큰 쪽 테이블을 읽어 해시 테이블을 탐색하면서 조인한다.
SELECT /*+ ordered use_hash(c) */
e.사원번호, e.사원명, e.입사일자, c.고객명, c.전화번호
FROM 사원 e, 고객 c
WHERE c.관리사원번호 = e.사원번호
AND e.입사일자 >= '19960101'
AND e.부서코드 = 'Z123'
AND c.최종주문금액 >= 20000
(1) 조건에 맞는 사원 데이터를 읽어 조인 컬럼인 사원번호를 해시 테이블 키값으로 해시 테이블을 생성한다. 사원번호를 해시 함수에 입력해서 반환된 값으로 해시 체인을 찾고, 그 해시 체인에 데이터를 연결한다. 해시 테이블은 PGA 영역에 할당된 Hash Area에 저장한다.
(2) 조건에 맞는 고객 데이터를 하나씩 읽어 앞서 생성한 해시 테이블을 탐색한다. 해시 함수가 반환한 값에 해당하는 해시 체인만 스캔하면 된다.
해시 조인이 바른 이유
- 해시 테이블을 PGA 영역에 할당하기 때문에, 래치 획득 과정 없이 PGA에서 빠르게 데이터를 탐색하고 조인하기 때문에 NL 조인보다 빠르다.
- (소트 머지 조인) '양쪽' 집합을 모두 정렬해서 PGA에 저장한다. PGA는 메모리 공간이 크지 않기 때문에 둘 중 하나의 테이블이라도 중대형 이상이라면, Temp 테이블스페이스를 사용할 경우가 있어 디스크에 쓰는 작업을 반드시 수반한다.
- (해시 조인) 양쪽 집합 중 어느 한쪽을 읽어 해시 맵을 만드는 작업이다. 둘 중 작은 집합을 해시 맵을 만들기 때문에 두 집합 모두 Hash Area에 담을 수 없을 정도로 큰 정도가 아니라면 Temp 테이블스페이스를 사용하지 않는다.
해시 조인 대용량 Build Input 처리
- T1, T2 모두 대용량 테이블이어서 인메모리 해시 조인이 불가능한 상황에서는 분할 정복 방식을 사용한다.
- 파티션 단계 : 조인 컬럼에 해시 함수를 적용하여, 반환된 해시 값에 따라 동적으로 파티셔닝 한다. 독립적으로 처리할 수 있는 여러 개의 작은 서브 집합으로 분할함으로써 파티션 짝을 생성한다.
- 조인 단계 : 각 파티션 짝에 대해 하니씩 조인을 수행한다. 각각에 대한 Build Input과 Probe Input은 독립적으로 결정된다. 파티션하기 전 어느 쪽이 작은 테이블이었는지에 상관없이 각 파티션 짝별로 작은 쪽을 Build Inout으로 선택하고 해시 테이블을 생성한다. 해시 테이블을 생성하고 나면 반대쪽 파티션 로우를 하나씩 읽으면서 해시 테이블을 탐색한다.
NL 조인 vs 해시 조인 vs 소트 머지 조인
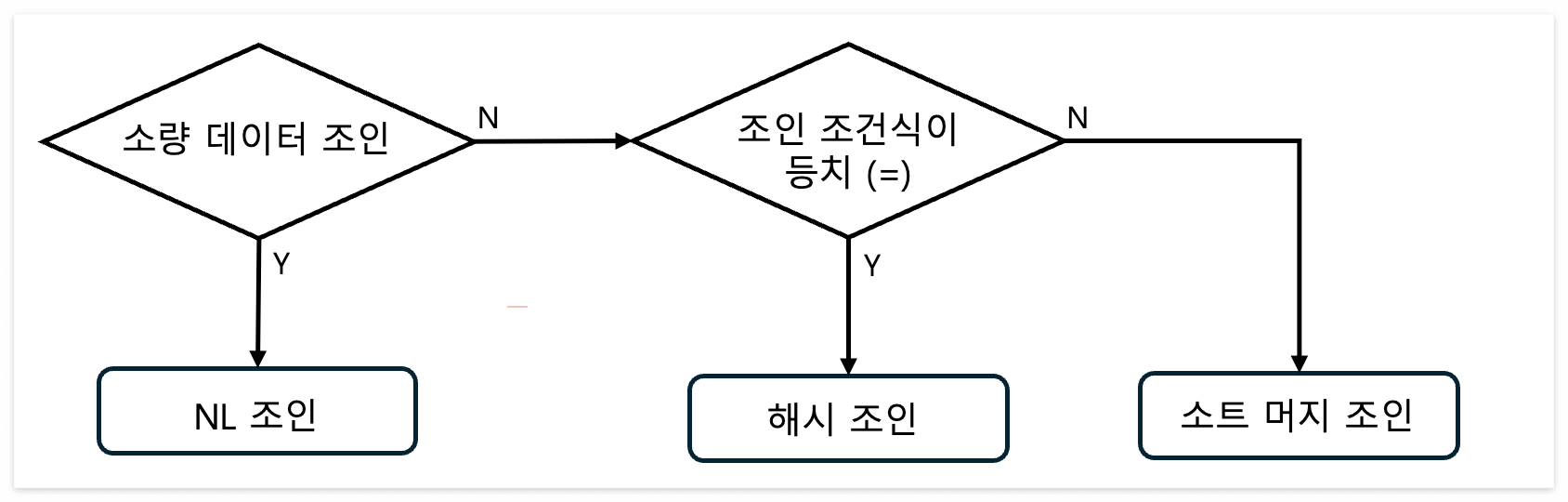
- 소량 데이터 조인할 때 → NL 조인
- 대량 데이터 조인할 때 → 해시 조인
- 대량 데이터 조인인데 해시 조인으로 처리할 수 없을 때 (조인 조건식이 등치 조건이 아닐 때) → 소트 머지 조인
- NL 조인 기준으로 최적화했는데도 랜덤 액세스가 많아 만족할만한 성능을 낼 수 없는 경우도 대량 데이터 조인에 해당한다.
NL 조인을 가장 먼저 고려해야 하는 이유
- NL 조인 위주로 처리하려면 인덱스를 세심하게 설계해야 하는 부담이 있고, 심지어 해시 조인이 약간 빠른 경우도 존재한다.
- (NL 조인) NL조인에 사용하는 인덱스는 영구적으로 유지하면서 다양한 쿼리를 위해 공유 및 재사용하는 자료구조이다.
- 반면에, 해시 테이블은 단 하나의 쿼리를 위해 생성하고 조인이 끝나면 소멸하는 자료구조이다. 따라서 수행시간이 짧으면서 수행빈도가 매우 높은 쿼리를 해시 조인으로 처리하면 CPU와 메모리 사용률이 크게 증가한다.
- 해시 조인은 수행 빈도가 낮고, 쿼리 수행 시간이 오래 걸리고, 대량 데이터를 조인할 때 사용한다. (배치, DW, OLAP성 쿼리)
- OLTP 환경에서 NL 조인으로 0.1초 걸리는 쿼리를 0.01초로 단축할 목적으로 해시 조인을 사용하는 것은 가급적 자제해야한다.
책 읽고 정리하는 과정
1. '친절한 SQL 튜닝' 책을 정독하며, 중요한 부분 바로바로 타이핑
2. 한 챕터가 끝나면, 타이핑한 부분을 복습하며 관련 구글링 및 재정리
NL 조인
조인의 기본은 NL 조인이다. NL 조인은 인덱스를 이용한 조인이다.
- 중첩 루프문의 수행 구조를 사용한다.
- NL 조인은 양쪽 테이블 모두 인덱스를 이용한다. '인덱스를 이용한 조인 방식'
Execution Plan
-------------------------------------------
SELECT STATEMENT Optimizer=ALL_ROWS
NESTED LOOPS
TALBE ACCESS (BY INDEX ROWID) OF '사원' (TABLE)
INDEX (RANGE SCAN) OF '사원_X1' (INDEX)
TALBE ACCESS (BY INDEX ROWID) OF '고객' (TABLE)
INDEX (RANGE SCAN) OF '고객_X1' (INDEX)
위쪽 사원 테이블 기준으로 아래쪽 고객 테이블과 NL 조인한다. 각 테이블을 액세스할 때 인덱스를 이용한다.
SELECT /*+ ordered use_nl(c) */
...
FROM 사원 e, 고객 c
- NL 조인힌트 use_nl 힌트, c와 조인할 때는 NL 방식으로 조인
- ordered 힌트는 FROM 절에 기술한 순서대로 조인하라고 지시
- 사원 테이블(driving 또는 Outer Table) 기준으로 고객 테이블 (inner 테이블)과 NL 방식으로 조인
- ordered 대신 leading 힌트도 있다.
SELECT /*+ leading(C, A, D, B) user_nl(A) use_nl(D) user_hash(B) */ *
FROM A, B, C, D4
WHERE ...
P.263
4.1.4 NL 조인 튜닝 포인트
4.1.5 NL 조인 특징 요약
- 랜덤 액세스 위주의 조인 방식, 레코드 하나를 읽으려고 블록을 통째로 읽는 랜덤 액세스 방식은 설령 메모리 버퍼에서 빠르게 읽더라도 비효율이 존재한다.
- 한 레코드씩 순차적으로 진행,
- 인덱스 구성 전략이 특히 중요하다. 조인 컬럼에 대한 인덱스가 있느냐 없느냐, 있다면 컬럼이 어떻게 구성됐느냐에 따라 조인 효율이 크게 달라진다.
- 소량 데이터를 주로 처리하거나 부분범위 처리가 가능한 온라인 트랜잭션 처리 시스템에 적합한 조인 방식이다.
소트 머지 조인
- 조인 컬럼에 인덱스가 없을 때, 대량 데이터 조인이어서 인덱스가 효과적이지 않을 때, 옵티마이저는 NL 조인 대신 소트 머지 조인이나 해시 조인을 선택한다.
- 해시 조인을 잘 쓰지만, 해시 조인을 사용할 수 없는 상황에서 대량 데이터를 조인하고자 할 때 여전히 유용하다.
- 소트 단계와 머지 단계
- 소트 단계 : 양쪽 집합을 조인 컬럼 기준으로 정렬한다.
- 머지 단계 : 정렬한 양쪽 집합을 서로 머지한다.
- use_merge 힌트로 유도한다.
- 277 기본 메커니즘 정리하기.
4.2.3 소트 머지 조인이 빠른 이유
- NL 조인은 대량 데이터 조인할 때 성능이 매우 느리다.
- 소트 머지 조인은 Sort Area에 미리 정렬해둔 자료구조를 이용한다는 점만 다를 뿐 조인 프로세싱 자체는 NL 조인과 동일하다.
NL 조인의 단점
- NL 조인의 경우 인덱스를 이용하는 조인 방식이기 때문에 조인 과정에서 액세스하는 모든 블록을 랜덤 액세스 방식으로 건건이 DB 버터캐시를 경유해서 읽는다. 즉, 인덱스든 테이블이든, 읽는 모든 블록에 래치 획득 및 캐시버퍼 체인 스캔 과정을 거친다. 버퍼캐시에서 찾지 못한 블록을 건건이 디스크에 읽어 드린다. 인덱스를 이용하기에 인덱스 손익분기점 한계를 드러낸다.
반면, 소트 머지 조인
- 양쪽 테이블로부터 조인 대상 집합을 일괄적으로 읽어 PGA에 저장한 후 조인한다. PGA는 프로세스만 위한 독립적인 메모리 공간이므로 데이터를 읽을 때 래치 획득 과정이 없다.
4.2.4 소트 머지 조인의 주용도
- 해시 조인은 조인 조건싱이 등치 조인이 아닐 때 사용할 수 없다는 단점이 있어, 그런 경우 소트 머지 조인을 사용한다.
- 사용처 : 조인 조건식이 등치(=) 조건이 아닌 대량 데이터 조인, 조인 조건식이 아예 없는 조인(카테시안 곱)
해시 조인
- NL 조인은 인덱스를 사용하는 조인 방식이기 때문에 인덱스 구성에 다른 성능 차이가 크다. 인덱스를 아무리 완벽하게 구성해도 랜던 I/O 때문에 대량 데이터 처리에 불리하고, 버퍼 캐시 히트율에 따라 들쭉날쭉한 성능을 보인다.
- 반면에 소트 머지 조인과 해시 조인은 대량 데이터를 조인할 때 NL 조인 보다 빠르고, 일정한 성능을 보인다.
- 소트 머지 조인은 항상 양쪽 테이블을 정렬하는 부담이 있지만, 해시 조인은 그런 부담도 없다.
기본 메커니즘
- Builder 단계 : 작은 쪽 테이블을 읽어 해시 테이블을 생성한다.
- Probe 단계 : 큰 쪽 테이블을 읽어 해시 테이블을 탐색하면서 조인한다.
- use_hash 힌트로 유도한다.
- Builde 단계, 조건에 해당하는 사원 데이터를 읽어 해시 테이블을 생성한다. 이때 조인 컬럼인 사원번호를 해시 테이블 키 값으로 사용한다. 해시 테이블은 PGA 영역에 할당된 Hash Area 에 저장한다. 만약 해시 테이블이 커 PGA에 담을 수 없으면 Temp 테이블스페이스에 저장한다.
- Probe 단계, 아래 조건에 해당하는 고객 데이터를 하나씩 읽어 앞서 생성한 해시 테이블을 탐색한다. 즉 관리사원번호를 해시 함수에 입력해서 반환된 값으로 해시 체인을 찾고 그 해시 체인을 스캔해서 값이 같은 사원번호를 찾는다. 찾으면 조인 성공 못 찾으면 시래한 것이다.
- 빠른 이유
- Hash Area에 생성한 해시 테이블을 이용한다는 점만 다를 뿐 조인 프로세싱 자체는 NL 조인과 동일하다.
- 해시 테이블을 PGA 영역에 할당하기 떄문에 빠르다. NL 조인은 Outer 테이블 레코드마다 Inner 쪽 테이블 레코드를 읽기 위해서 래치 획득 및 캐시버퍼 체인 스캔 과정을 반복하지만, 해시 조인은 래치 획득 과정 없이 PGA에서 빠르게 데이터를 탐색하고 조인한다.
- 왜 소트 머지 조인보다도 빠를까?
- PGA에서 데이터를 탐색하는 알고리즘 차이도 있지만, 조인 오페레이션을 시작하기 전에 사전 준비작업에 기인한다.
- 소트 머지 조인에서 사전 준비작업은 '양쪽' 집합을 모두 정렬해서 PGA에 담는 작업이다. PGA는 그리 큰 메모리 공간이 아니므로 두 집합 중 어느 하나가 중대형 이상이면, Temp 테이블스페이스, 즉 디스크에 쓰는 작업을 반드시 수반한다.
- 해시 조인에서 사전 준비작업은 양쪽 집합 중 어느 '한쪽'을 읽어 해시 맵을 만드는 작업이다. 둘 중 작은 집합을 해시 맵 Build Input으로 선택하므로 두 집합 모두 Hash Area에 담을 수 없을 정도로 큰 경우가 아니면 Temp 테이블스페이스, 즉 디스크에 쓰는 작업이 전혀 일어나지 않는다.
- NL 조인처럼 조인 과정에서 발생하는 랜덤 액세스 부하가 없고, 소트 머지 조인처럼 양쪽 집합을 미리 정렬하는 부하도 없다.
- 해시 테이블을 만드는 비용은 수반되지만, 둘 중 작은 집합을 Build Input으로 선택하므로 대개는 부담이 적다.
- 4.3.3 대용량 Build Input 처리
- T1, T2 모두 대용량 테이블이어서 인메모리 해시 조인이 불가능한 상황
- 분할 정복 방식 사용
- 파티션 단계 : 조인 컬럼에 해시 함수를 적용하여, 반환된 해시 값에 따라 동적으로 파티셔닝한다. 독립적으로 처리할 수 있는 여러 개의 작은 서브 집합으로 분할함으로써 파티션 짝을 생성하는 단계
- 조인 단계 : 각 파티션 짝에 대해 하니씩 조인을 수행한다. 각각에 대한 Build Input과 Probe Input은 독립적으로 결정된다. 파티션하기 전 어느 쪽이 작은 테이블이었는지에 상관없이 각 파티션 짝별로 작은 쪽을 Build Inout으로 선택하고 해시 테이블을 생성한다. 해시 테이블을 생성하고 나면 반대쪽 파티션 로우를 하나씩 읽으면서 해시 테이블을 탐색한다.
- 4.3.4 해시 조인 실행계획 제어
- Hash JOIN 바로 아래, 해시 테이블을 생성 후에, 아래쪽에서 읽은 조인 키값으로 해시 테이블을 탐색하면서 조인한다.
- ordered를 사용하지 않고 use_hash 힌트만 사용했으면, Build Input을 옵티마이저가 선택하는데 일반적으로 카디널리티가 작은 테이블 선택한다. (ordered 나 leading을 사용하여 Build Input을 직접 설정가능)
- 세 개 이상 테이블 해시 조인
- 4.3.5 조인 메소드 선택 기준
- 해시조인, 인덱스 설계에 공들이지 않아도 되니 편하기까지 하다. 수행빈도가 매우 높은 쿼리에 대해선 특히 그렇다.
- 297 표 그리기.
- NL 조인을 가장 먼저 고려해야하는 이유
- NL 조인에 사용하는 인덱스는 영구적으로 유지하면서 다양한 쿼리를 위해 공유 및 재사용하는 자료구조이다. 반면 해시 테이블은 단 하나의 쿼리를 위해 생성하고 조인이 끝나면 소멸하는 자료구조이다. 따라서 수행시간이 짦으면서 수행빈도가 매우 높은 쿼리를 해시 조인으로 처리하면 CPU와 메모리 사용률이 크게 증가한다.
- 해시 조인은 수행 빈도가 낮고, 쿼리 수행 시간이 오래 걸리고, 대량 데이터를 조인할 때 사용한다. (배치 프로그램, DW, OLAP성 쿼리)
- OLTP 환경에서 NL 조인으로 0.1초 걸리는 쿼리를 0.01초로 단축할 목적으로 해시 조인을 사용하는 것은 가급적 자제해야한다.
4.4 서브쿼리 조인
- 옵티마이저가 서브쿼리 조인을 어떻게 처리하는 지 이해, 원하는 방식으로 실행계획을 제어할 수 있어야 튜닝 가능
- 서브쿼리 : 하나의 SQL문 안에 괄호로 묶은 별도의 쿼리 블록을 말한다.
-- 인라인 뷰 : FROM 절에 사용한 서브쿼리
-- 중첩된 서브 쿼리 : 결과집합을 한정하기 위해 WHERE절에 사용한 서브쿼리
-- 스칼라 서브쿼리 : 한 레코드당 정확히 하나의 값을 반환하는 서브쿼리.
4.4.2 서브쿼리와 조인
- 메인쿼리와 서브쿼리 간에는 부모와 자식이라는 종속적인 관계가 존재한다.
- 메인쿼리 건수만큼 값을 받아 반복적으로 필터링하는 방식으로 실행
필터 오퍼레이션
- 서브쿼리를 필터 방식으로 처리하게 하려고 의도적으로 no_unnest 힌트를 사용했다. 서브쿼리를 풀어내지 말고 그대로 수행하라고 옵티마이저에 지시하는 힌트
- 필터 오퍼레이션은 기본적으로 NL 조인과 처리 루틴이 동일하다. 범위 처리도 가능하다.
- 차이점
-- 메인쿼리의 한 로우가 서브쿼리의 한 로우와 조인에 성공하는 순간 진행을 멈추고 메인쿼리의 다음 로우를 계속 처리한다
-- 캐싱기능을 갖는다.
-- 일반 NL 조인과 달리 메인쿼리에 종속되므로 조인 순서가 고정된다. 항상 메인쿼리가 드라이빙 집합이다.
서브쿼리 Unnesting
- 서브쿼리를 그대로 두면 필터 방식을 사용할 수 밖에 없지만, Unnesting 하고 나면 일반 조인문처럼 다양한 최적화 기법을 사용할 수 있다.
- 필터방식은 항상 메인쿼리가 드라이빙 집합이지마느 Unnesting된 서브쿼리는 메인 쿼리 집합보다 먼저 처리될 수 있다.
4.4.3 뷰와 조인
4.4.4 스칼라 서브쿼리 조인
'정리' 카테고리의 다른 글
| [Redis] redis.conf 기준 Redis 백업 방법 정리 (RDB vs AOF) (0) | 2024.10.28 |
|---|---|
| [Redis] Redis 캐싱 전략 패턴 정리 (0) | 2024.10.20 |
| [친절한 SQL 튜닝] 인덱스 튜닝 (2) : 인덱스 스캔 효율화, 인덱스 설계 (0) | 2024.06.13 |
| [친절한 SQL 튜닝] 인덱스 튜닝 (1) 테이블 액세스 최소화, 부분범위 처리 활용 (1) | 2024.05.05 |
| [친절한 SQL 튜닝] 인덱스 기본 (1) | 2024.04.21 |



