이제 중간 발표도 끝났겠다, 다시 열심히 블로그를 작성하려고 한다. "마이브러리" 프로젝트를 진행하면서 이슈도 많았고, 많은 것을 배우고 개발 중이었기 때문에 포스팅할 내용들이 너무 많다.. 다시 꾸준하게 블로그를 작성해봐야겠다.!!
SWM에서 "마이브러리" 프로젝트를 진행하는 과정에 있어서 외부 API를 사용하여 도서의 정보를 가져오는 기능이 있었다.
매 사용자의 요청마다 외부 API를 호출하기 때문에 캐시를 적용하여, 외부 API 호출량도 줄이고 응답 속도도 줄일 것이라 기대하고 캐시를 도입하였다.
캐시를 도입한 이유
- 외부 API를 사용하기 때문에 외부 API 상태에 따라 응답 속도에 영향을 받는다. 길게는 2초 이상의 응답 속도가 걸린 적이 있다.
- 도서의 정보 데이터는 갱신이 자주 일어나지 않지만 참조는 빈번하게 일어나는 데이터이기 때문에 캐싱하기 적합한 데이터이다.
- 베스트셀러의 데이터는 갱신되는 일정 주기가 존재한다. 따라서 배치 작업을 통해 캐시를 갱신할 수 있고, 적절한 TTL을 지정할 수 있었다.
RedisClusterConfig 설정
@Configuration
@EnableCaching
@Profile({"prod", "dev"})
public class RedisClusterConfig {
@Value("${spring.redis.cluster.nodes}")
private List<String> clusterNodes;
@Bean
public RedisConnectionFactory redisConnectionFactory() {
RedisClusterConfiguration clusterConfiguration = new RedisClusterConfiguration(clusterNodes);
return new LettuceConnectionFactory(clusterConfiguration);
}
@Bean
public RedisTemplate<?, ?> redisTemplate() {
RedisTemplate<byte[], byte[]> redisTemplate = new RedisTemplate<>();
redisTemplate.setKeySerializer(new StringRedisSerializer());
redisTemplate.setValueSerializer(new StringRedisSerializer());
redisTemplate.setHashKeySerializer(new StringRedisSerializer());
redisTemplate.setHashValueSerializer(new StringRedisSerializer());
redisTemplate.setConnectionFactory(redisConnectionFactory());
return redisTemplate;
}
@Bean
public CacheManager cacheManager(RedisConnectionFactory cf) {
RedisCacheManagerBuilder builder = RedisCacheManagerBuilder.fromConnectionFactory(cf);
RedisCacheConfiguration configuration = RedisCacheConfiguration.defaultCacheConfig()
.disableCachingNullValues()
.entryTtl(Duration.ofDays(1L))
.serializeKeysWith(RedisSerializationContext.SerializationPair.fromSerializer(new StringRedisSerializer()))
.serializeValuesWith(RedisSerializationContext.SerializationPair.fromSerializer(new GenericJackson2JsonRedisSerializer()));
Map<String, RedisCacheConfiguration> cacheConfigurations = Arrays.stream(CacheKey.values())
.collect(Collectors.toMap(
CacheKey::getKey,
cacheKey -> RedisCacheConfiguration.defaultCacheConfig()
.entryTtl(Duration.ofSeconds(cacheKey.getExpireTimeSeconds()))
.prefixCacheNameWith(cacheKey.getPrefix() + "::")
));
return builder.cacheDefaults(configuration).withInitialCacheConfigurations(cacheConfigurations).build();
}
}위와 같이 RedisClusterConfig를 설정하였다. 기존에는 하나의 Redis만 구축했지만, 가용성과 안정성을 위해 직접 RedisCluster를 구축했다. RedisCluster 구축을 한 부분에 있어서는 추후에 포스팅을 할 예정이다.
Map<String, RedisCacheConfiguration> cacheConfigurations = Arrays.stream(CacheKey.values())
.collect(Collectors.toMap(
CacheKey::getKey,
cacheKey -> RedisCacheConfiguration.defaultCacheConfig()
.entryTtl(Duration.ofSeconds(cacheKey.getExpireTimeSeconds()))
.prefixCacheNameWith(cacheKey.getPrefix() + "::")
));Config 파일에서 집중적으로 볼 코드는 동적으로 캐시 설정을 생성하는 코드라고 생각한다.
동적으로 캐시를 설정함으로써 다양한 캐시 요구 사항을 유연하게 관리할 수 있다.
- 모든 캐시 데이터가 동일한 TTL(Time To Live)를 가질 필요 없다. 데이터의 성격과 특성에 따라 짧은 시간 동안만 유지할 필요 있는 데이터가 있고, 오랜 시간 동안 캐시할 데이터가 존재한다. 따라서 데이터마다 TTL를 다르게 설정할 수 있다.
- 캐시는 키-벨류로 관리되기 때문에, 키가 겹치는 일이 발생할 수 있다. 따라서 접두사(prefix)를 사용하여 캐시 항목을 분리 가능하다. 이를 통해 서로 다른 목적의 캐시 항목을 분리하고, 캐시 키 충돌을 방지할 수 있다.
자바의 Stream API를 사용하여 Redis 캐시 설정을 동적으로 생성하였고, 아래와 같은 enum 클래스를 통해 각 캐시의 설정값을 분리하였다. 따라서 만약 캐시 요구 사항이 생기면 Config 코드를 수정하지 않고, 각 enum 클래스에 코드를 추가함으로써 설정 추가가 가능하다.
@Getter
@RequiredArgsConstructor
public enum CacheKey {
BOOK_LIST_BY_CATEGORY("bookSearch", "bookListByCategory", CacheTTL.ONE_WEEK.getExpireTimeSeconds()),
BOOK_LIST_BY_SEARCH_KEYWORD("bookSearch", "bookListBySearchKeyword", CacheTTL.ONE_WEEK.getExpireTimeSeconds());
private final String prefix;
private final String key;
private final int expireTimeSeconds;
}CacheKey enum 클래스는 Cache의 prefix와 key, expireTimeSeconds를 매개변수로 받아 초기화한다.
@Getter
@RequiredArgsConstructor
public enum CacheTTL {
ONE_MONTH(60 * 60 * 24 * 30),
ONE_WEEK(60 * 60 * 24 * 7),
ONE_DAY(60 * 60 * 24),
ONE_HOUR(60 * 60),
ONE_MIN(60);
private final int expireTimeSeconds;
}캐시의 TTL 값을 저장하고 있는 enum 입니다. TTL 값을 enum으로 분리함으로써 아래와 같은 이점을 볼 수 있었다.
- 가독성이 향상, TTL 값을 숫자로 하드코딩된 값 보다 Enum을 통해 해당 값들의 의미를 명확하게 전달할 수 있다.
- 유지보수성이 개선, 하드코딩 된 TTL 값을 수정할 일이 있을 경우 일일이 찾아 수정하는 데에 불편함이 있을 수 있다.
@Cacheable 적용
@Cacheable(cacheNames = "bookListBySearchKeyword", key = "#request.keyword + '_' + #request.sort + '_' + #request.page", cacheManager = "cacheManager")
public BookSearchResultResponse searchWithKeyword(BookSearchServiceRequest request) {
...
return BookSearchResultResponse.of(bookSearchResultResponseElement, getNextRequestUrl(request));
}Spring Data Redis의 @Cacheable 어노테이션을 통해 편리한 캐시 추상화 기능을 사용할 수 있다.
@Transactional과 마찬가지로 AOP 방식으로 캐시 관련 로직을 핵심 비즈니스 로직으로부터 분리할 수 있고, 어노테이션을 통해 쉽게 적용할 수 있다. 또한 캐시 구현 기술에 종속되지 않도록 추상화된 서비스를 제공한다. 따라서 캐시 기술이 변경되더라도 애플리케이션 코드에는 영향을 주지 않는다.
- cacheNames : 실행 결과가 저장될 캐시 이름을 정의
- key : 캐시에 저장될 때 사용될 키 값을 정의
- cacheManager : 캐시를 관리하는 CacheManager의 빈 이름을 정의
@Cacheable의 캐싱 전략은 Look-Aside Caching 패턴을 따른다.
- cache에 존재할 경우 cache에서 가져오고 (cache hit),
- cache에 존재하지 않을 경우 (cache miss), 도서 검색 api를 호출하여 데이터를 반환한 이후 그 결과를 redis에 저장한다.
@Cacheable 외에도 단순 캐시에 데이터를 저장하는 @CachePut, 캐시에 데이터를 삭제하는 @CacheEvict가 있다.
성능 측정 결과
캐시 미적용

캐시 적용
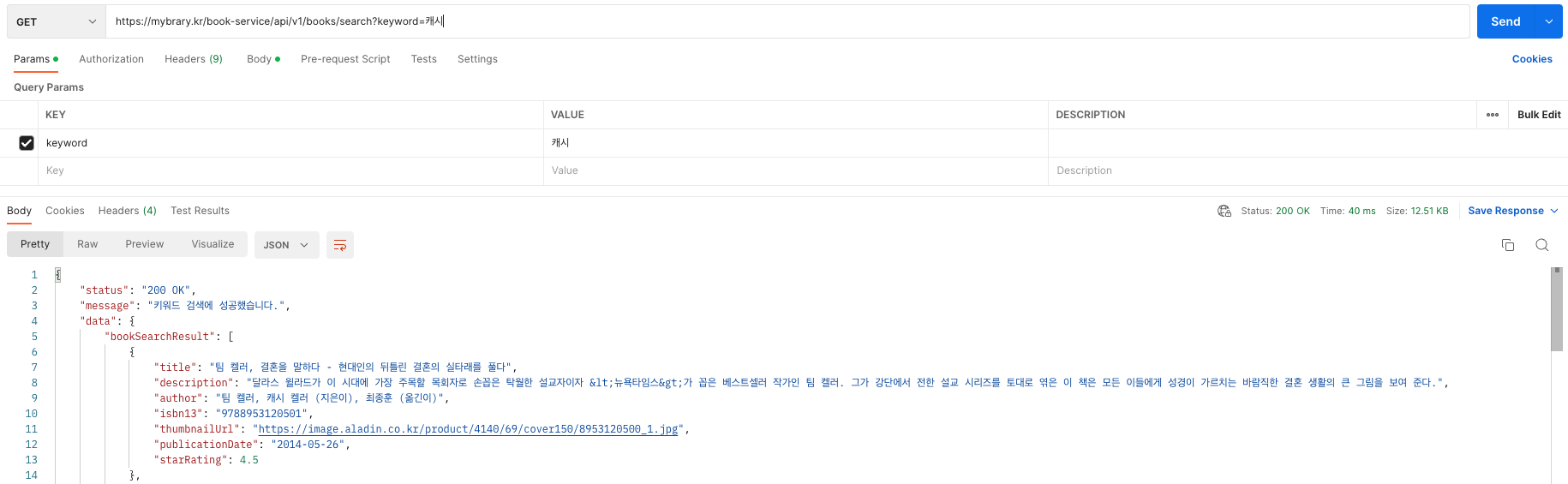
외부 API를 사용하였을 때 응답 속도는 길게는 2초가 넘게 걸리는 경우도 있었지만, 캐시를 적용한 이후 평균적으로 10배 정도의 성능을 향상할 수 있었다. (593 ms → 40 ms)
첫 요청에는 캐시가 적용되지 않고, 그다음 요청부터 캐시가 적용된다. 따라서 첫 번째 요청에 있어서는 캐시를 적용된 것보다 응답 시간이 길 수밖에 없다. 따라서 추후에 *Cache Warming을 통해 첫 요청에도 캐시를 적용시킬 수 있도록 개선할 예정이다.
*Cache Warming
캐시를 사전에 예열하는 과정이다. 시스템이 재시작 또는 배포 후 처음 시작될 때, 자주 접근되는 데이터는 아직 캐시에 로드되지 않아 초기 요청에서는 높은 대기 시간이 발생할 수 있습니다. 이러한 초기 대기 시간을 줄이기 위해, 시스템이 작동하기 전에 주요 데이터를 캐시에 미리 로드하는 것이다.
'개발 > Spring' 카테고리의 다른 글
| Resilence4J 서킷 브레이커 개념 및 적용하기 (4) | 2024.01.23 |
|---|---|
| [Spring] MyBatis 사용법 및 동적 쿼리 정리 (1) | 2024.01.09 |
| [Spring] @Async를 사용하여 비동기 처리 (+ 쓰기, 읽기 서비스 분리) (0) | 2023.08.12 |
| [Spring] JPA Fetch Join 사용시, MultipleBagFetchException 발생 (3) | 2023.08.03 |
| [Test] 외부 API 테스트하기 (+ RestTemplateBuilder) (0) | 2023.07.06 |
